【RL】PPO算法入门#
强化学习(Reinforcement Learning, RL)在机器人领域的应用本质上都是为了解决一个核心问题:让机器人通过与环境的交互,自主学习到一个最优的策略(Policy),从而完成特定任务。这些方法都满足一个基本的框架:
- 感知(Perception): 机器人通过传感器感知当前环境的状态 st。
- 决策(Decision): 机器人的策略 π 根据当前状态 st 决定要执行的动作 at。
- 行动(Action): 机器人执行动作 at,与环境发生交互。
- 学习(Learning): 环境根据机器人的动作反馈一个新的状态 st+1 和一个奖励信号rt。算法利用这个反馈信息 (st,at,rt,st+1) 来更新和优化策略 π 。
从数学原理上讲,所有这些强化学习方案的共同基础是马尔可夫决策过程(Markov Decision Process, MDP)
在上图中,机器人通过感知环境,获取状态,通过Actor中的策略 π 输出对应的行动与环境进行交互,进而状态改变。不断重复上述过程,直到任务结束,这样就得到了一个由不同时刻Actor的输入与输出组成的序列 τ。
PG(Policy Gradient)#
策略梯度算法(Policy Gradient, PG)则是将其看作一个基于参数 θ 随机策略 πθ ,通过寻找一个最优策略并最大化这个策略在环境中的期望回报:
πθ∗=argθmaxJ(θ)=argθmaxEs0[Vπθ(s0)]=argθmaxEπθ[t=0∑∞r(st,at)](1)对于我们要训练的一个任务而言,初始的时候,由于Actor会在不同的state做出怎样的action是不确定的,因此发生序列 τ 的概率分布为:
pθ(τ)=p(s1)pθ(a1∣s1)p(s2∣s1,a1)pθ(a2∣s2)p(s3∣s2,a2)⋯=p(s1)t=1∏Tpθ(at∣st)p(st+1∣st,at)由上,我们就可以得到在序列 τ 下,以 θ 为参数的策略获得的累计奖励(这里的累计奖励就是 (1) 中的价值函数)为:
J(θ)=Eτ∼pθ(τ)[R(τ)]=τ∑R(τ)pθ(τ)其中,Eτ∼pθ(τ) 的含义为在在策略 πθ 下,轨迹 τ 按照分布 pθ(τ) 随机产生的期望。要求 J(θ) 的极大值,可以通过梯度上升法进行求解,也就需要求解 ∇θJ(θ)。
∇θJ(θ)=τ∑R(τ)∇pθ(τ)对上式而言,并不能直接求和,因为 pθ(τ) 过于庞大,因此需要对上式进行一些化简:
∇θJ(θ)=τ∑R(τ)pθ(τ)pθ(τ)∇pθ(τ)由链式法则我们有:
τ∑R(τ)pθ(τ)pθ(τ)∇pθ(τ)=τ∑R(τ)pθ(τ)∇logpθ(τ)显然有 ∑τpθ(τ)=1,因此有:
τ∑R(τ)pθ(τ)∇logpθ(τ)=Eτ∼pθ(τ)[R(τ)∇logpθ(τ)]进而可以对上式进行数值求解(Monte Carlo method):
Eτ∼pθ(τ)[R(τ)∇logpθ(τ)]≈N1n=1∑NR(τn)∇logpθ(τn)=N1n=1∑Nt=1∑TnR(τn)∇logpθ(atn∣stn)就可以通过实际采集的样本求解目标函数 J(θ) 的梯度。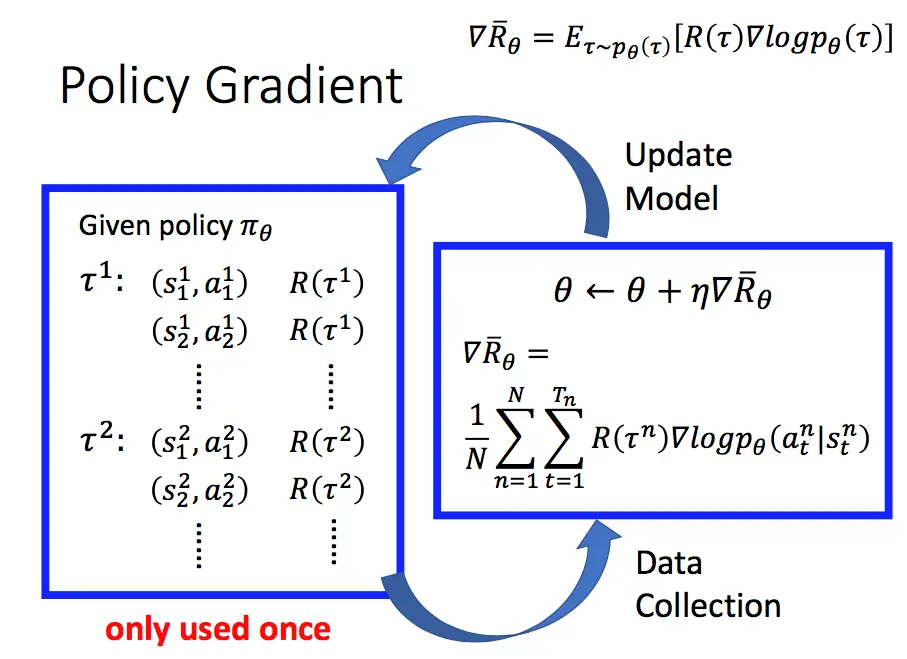
从上述流程图中不难看出,采集到的数据都是当前策略与环境之间交互的结果。因此策略梯度算法是一种在线策略(on-policy)算法,需要根据当前采样的数据来计算梯度。在线策略需要每迭代一步就重新采集数据,这样的训练无论是从时间还是内存上都是巨大的消耗,因此我们需要考虑如何才能让模型能反复从一组采样数据上学习 θ′ 另 J(θ′)>J(θ) 。
TRPO (Trust Region Policy Optimization)#
由于初始状态 s0 的分布和策略无关,因此上述策略 πθ 下的优化目标 J(θ) 可以写成在新策略 πθ′ 的期望形式:
J(θ)=Es0[Vπθ(s0)]=Eπθ′[t=0∑∞γtVπθ(st)−t=1∑∞γtVπθ(st)]=−Eπθ′[t=0∑∞γt(Vπθ(st+1)−Vπθ(st))]对两个参数之间的目标函数做差可得(具体推导过程见TRPO单调性证明):
J(θ′)−J(θ)=Es0[Vπθ′(s0)]−Es0[Vπθ(s0)]=Eπθ′[t=0∑∞γtr(st,at)]+Eπθ′[t=0∑∞γt(γVπθ(st+1)−Vπθ(st))]=Eπθ′[t=0∑∞γt(r(st,at)+γVπθ(st+1)−Vπθ(st))]=Eπθ′[t=0∑∞γtAπθ(st,at)]=1−γ1Es∼νπθ′Ea∼πθ′(⋅∣s)[Aπθ(s,a)]其中 Aπθ 为优势函数(Advantage Function)。上述的式子说明,只要找到的策略满足:
Es∼νπθ′Ea∼πθ′(⋅∣s)[Aπθ(s,a)]≥0就可以满足 J(θ′)>J(θ)。为了求解该式,TRPO选择了使用原策略 πθ 的状态分布做了近似处理,并使用重要性采样对动作分布进行处理,得到目标函数 Lθ(θ′) ,并使用KL散步保证这两者之间足够接近。TRPO优化公式如下:
θ′max Lθ(θ′)=J(θ)+Es∼νπθEa∼πθ(⋅∣s)[πθ(a∣s)πθ′(a∣s)Aπθ(s,a)]s.t. Es∼νπθk[DKL(πθk(⋅∣s),πθ′(⋅∣s))]≤δPPO(Proximal Policy Optimization)#
PPO算法与TRPO算法的区别在于对于参数 θ 的约束。为了模型能从示范分布 θ′ 中学习参数,就必须让我们学习的参数 θ 与示范数据中的 θ′ (未知)的分布差距不大。TRPO使用KL散度作为约束项来约束优化目标。而PPO算法直接将约束放在优化目标函数上。目前的PPO算法有两种实现方式:近端策略优化惩罚(PPO-penalty)与近端策略优化裁剪(PPO-clip)
PPO-penalty#
JPPOθ′(θ)=Jθ′(θ)−βKL(θ,θ′)通过KL散度动态调整惩罚参数 β ,更像是使用惩罚法去求解TRPO算法。
PPO-clip#
clip的做法就更加直接,如果我学习的参数 θ 与示范中的参数分布 θ′ 的分布差距过大,我就对这一项进行一定程度的裁剪
JPPOθk≈(st,at)∑min(pθk(at∣st)pθ(at∣st)Aθk(st,at), clip(pθk(at∣st)pθ(at∣st),1−ε,1+ε)Aθk(st,at))其中 ε 为超参数。
PPO 代码已由OpenAI开源至Github:
Waiting for api.github.com...
对数导数技巧#
对于 f(x) 有:
∇f(x)=f(x)∇logf(x)证明:
由链式法则求解 ∇logf(x) 有:
∇logf(x)=f(x)1∇f(x)移项可得上式。
